
This post is part of a blog series recapping highlights from our webinar series, where industry experts share their knowledge and field lessons from utilities building internal network security monitoring (INSM) programs.
In the fifth episode, we turned to the requirement at the very heart of CIP-015: detecting anomalous network activity. I was joined by my Nozomi Networks colleague Chris Grove, Director of Cybersecurity Strategy. I come at this topic from a utilities and NERC CIP background. I’ve run NERC CIP programs and have been active in the community for years. Chris comes at it from the detection-engineering side. That juxtaposition — someone who knows compliance deeply alongside someone who lives in detection — is what makes these conversations worth having, and every time we have one, I learn something new.
“Anomalous”: A Word Without a Definition
NERC CIP-015-1 Requirement R1 asks entities to do two things: implement one or more methods to detect anomalous network activity (Part 1.2) and use one or more methods to evaluate that activity to determine further action (Part 1.3). Everything in the requirement hangs on a single word, “anomalous,” and here’s the catch: it isn’t a NERC glossary term.
The drafting team’s technical rationale describes anomalous as “unexpected, undesired, unusual or undetermined network traffic.” Merriam Webster defines it as “Inconsistent with or deviating from what is usual, normal or expected; marked by incongruity or contradiction.” Plenty of practitioners reach for other meanings entirely including malicious activity, unauthorized traffic or deviation from a baseline. Words really matter here, because when something isn’t defined for you, two things follow:
- You have to define it yourself
- How you define it will steer everything your program does downstream
I’ll say upfront that it isn’t wise to equate “anomalous” with “malicious.” Why? Because you rarely know whether something is malicious at the moment of detection. You learn that only after evaluation and root-cause analysis.
Context Is Everything in Anomaly Detection
Think about a home fire alarm. When it goes off, is that an anomaly? To someone at 3:00 a.m., absolutely. To the engineer who designed the system? No, it’s doing exactly what it was built to do when it senses smoke. And on a Friday night when someone is blackening fish on the stove? Maybe. Context is everything. Without context, anomalies are just events described by a pattern, and one person’s anomaly is another person’s day-to-day operations.
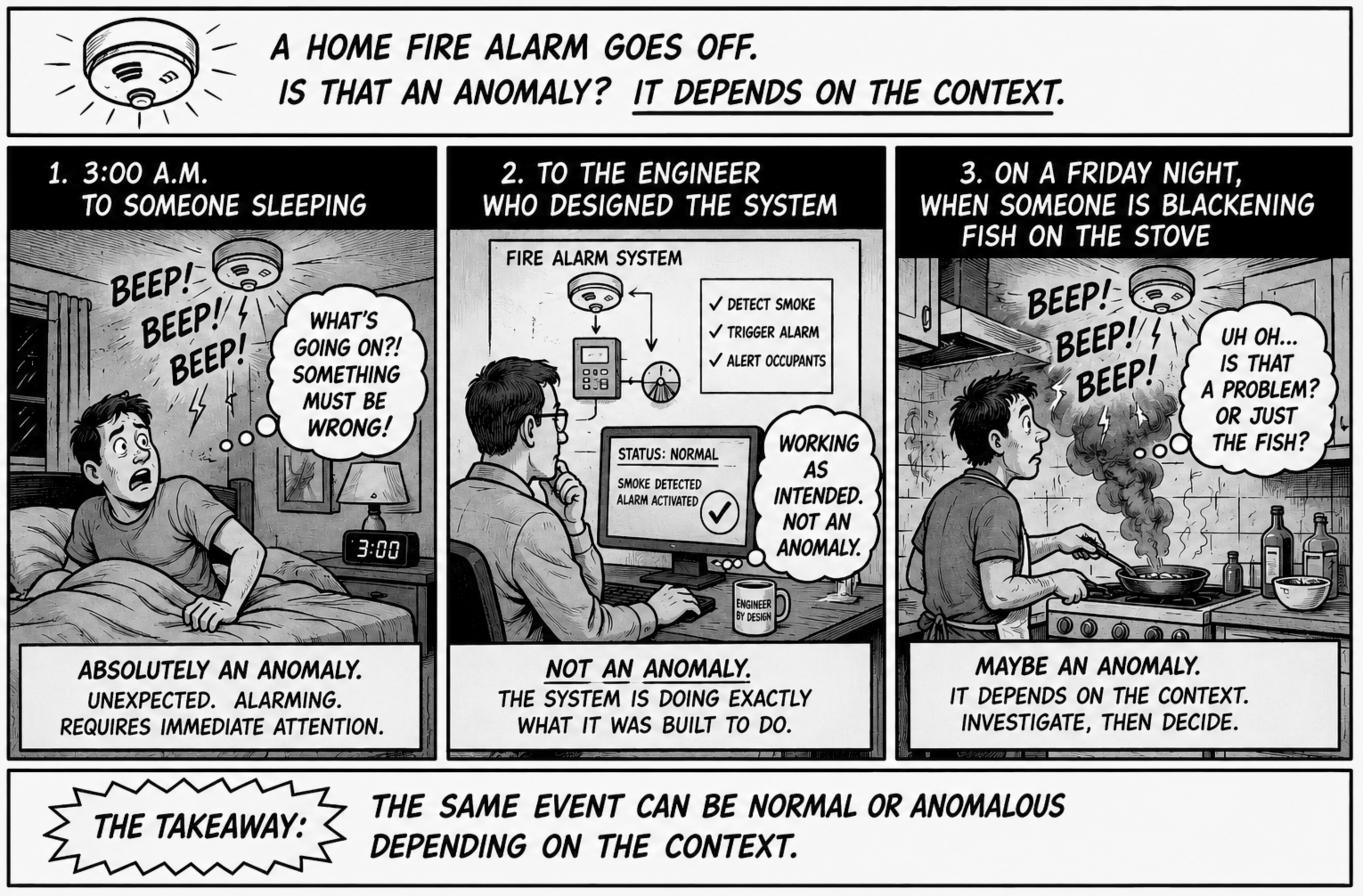
That plays out constantly in OT. A vibration sensor on a turbine sits quietly at zero under normal conditions, then flips to one. To the control system, that’s expected behavior and can result in an early detection of a physical issue. From a baseline-deviation standpoint, it’s 100% an anomaly, because your normal state was zero and now it isn’t. Whether you want to capture it as one depends entirely on your organization.
Known, Unknown and Why You Need Both
In any control-system network there are things we know about and things we don’t. We may know the engineer’s station, the normal logins, the protocol used to send a command to an IED. But it’s the unknowns that are harder. If someone issues a command from that station, do we know if it's malicious or not? If we don’t have visibility, we may not even see the command sent and instead only see the status change. The hard part is the unknown unknowns: what we don’t know we don’t know. In OT security, it’s the packet using an allowed protocol but heading in a new direction, or an HMI suddenly writing to an IED instead of reading from it.
You can’t meet the intent of INSM with signatures alone, but you don’t necessarily have to reach full process-level depth either. That’s a risk-based call you justify within your own program based on your organization and team.
Signatures are how we catch the knowns: known malware, known adversary activity, known indicators of compromise (IOCs). They’re high-value and, when written well, low-noise. But signatures always lag. That’s the nature of detection engineering, and it’s a big part of why we have CIP-015 at all. The standard grew out of SolarWinds and similar attacks that slipped past traditional, signature-based detection on the ESP edge. Anomaly detection is where you catch the adversary who is living off the land, abusing legitimate tools and credentials rather than tripping a signature.
So, if you want to know whether you need anomaly detection or an intrusion detection system looking for known attacks, the honest answer is both. They run side by side, and the full picture of what’s happening is almost always a combination of the two.
Anomaly Detection Methods
The technical rationale for CIP-015 identifies four anomaly detection methods. They’re best treated as a toolbox rather than a menu where you pick just one:
- Signature-based detections identify defined anomalies such as known malicious traffic, signature rules and other IOCs. You’re literally writing a rule.
- Behavioral detections use math to surface statistically significant deviations. Baselines here can be static (fixed until regenerated) or dynamic (continuously adjusted). A data stream from a relay to an RTAC that normally runs at one megabit and suddenly jumps to 10 is a statistical anomaly worth investigating, although it could just as easily be a firmware upgrade as something hostile.
- Configuration checking catches unwanted configurations and hygiene issues, including misconfigured devices, SNMPv1 instead of v3, RDP without certificates or insecure remote tools. Even here, context rules: a protocol with known weaknesses may still be the right operational choice in a facility that uses it securely.
- Baseline deviation is the heart of much of what utilities are deploying for INSM. It could be a new device, new communication, new protocol, new function code: anything that’s a change from normal.
Baseline deviations are the most important to unpack, because the word “baseline” means different things at different depths. It’s most practical to think of it in terms of three levels:
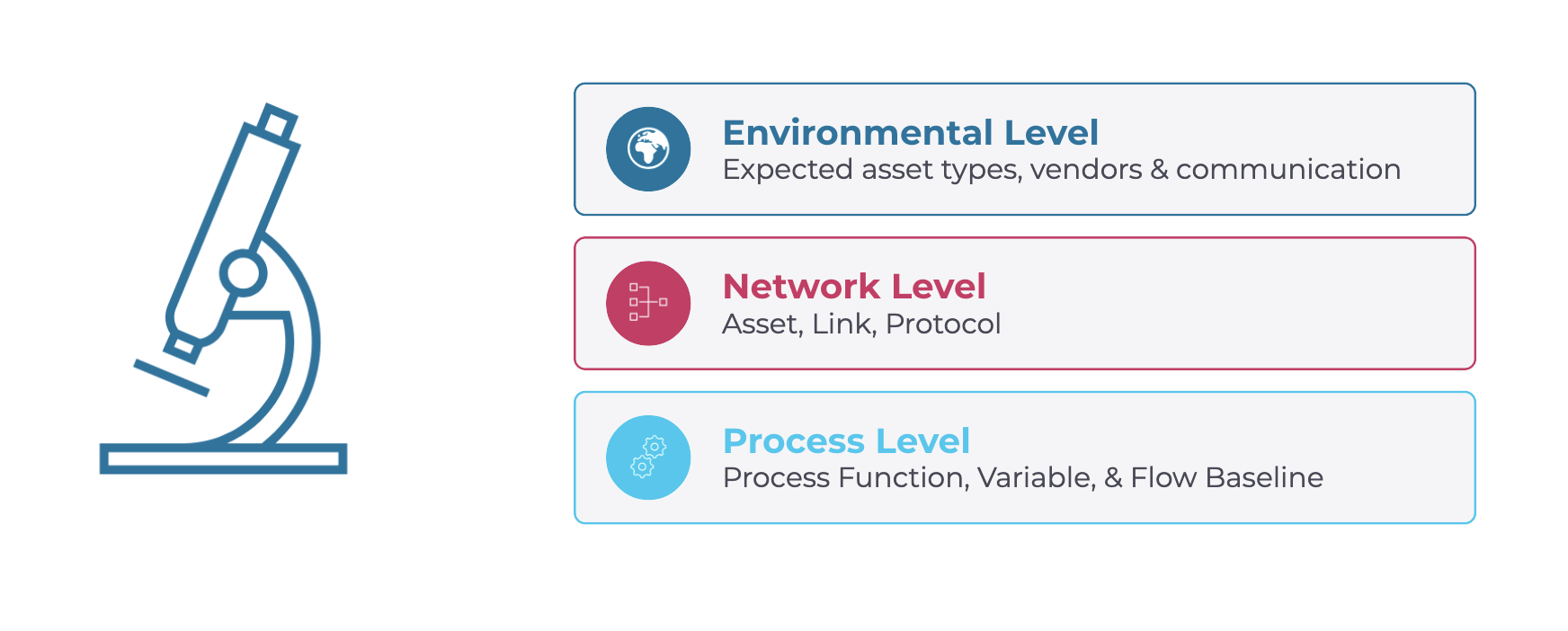
- Environmental level is the broad stroke. If you’re an SEL and DNP3 shop, then any device that isn’t an SEL or any industrial protocol that isn’t using DNP3 is a deviation.
- Network level zooms in to specific assets, links and protocols. A new device or a changed MAC or IP address, a new link between two assets, or a new protocol between two assets on a link would be a deviation.
- Process level goes all the way down to function codes, variables, values and flow. At this level, the values within the protocols matter. The deeper you go, the more value and visibility you gain, but the more noise and maintenance you take on.
Match Your Anomaly Detection Strategy to Your Team and Environment
Detecting an anomaly is the start of a story, not the conclusion, which is why R1 Part 1.3 pairs evaluation with detection. A new laptop on the network doesn’t mean you shut the plant down; you evaluate the anomaly, ask someone to check it out and maybe accept the risk if it’s not malicious. Any anomaly detected can become part of what is expected once it is determined to be expected. This is often part of the tuning process, although care should be taken not to turn off alerts that may be valuable in an investigation but do not need to be triggered as anomalies.
For example, if you have known transient cyber assets, it may be better to have an alert fire when they‘re connected and then automatically mute them rather than turning them off, because when investigation time comes, those alerts are gold to provide correlation and context.
The right strategy ultimately has to match your capabilities. A large team with strong OT relationships can push toward process-level monitoring. A smaller team is better off focusing on the network level, leaning on behavioral and signature-based methods, and building from there rather than reaching beyond what it can actually support. Spreading your team too thin isn’t a strategy. You want to stay “left of bang,” which means looking across the network, the process and the environment, not just one of them.
Final Thoughts
The best practices come down to this: define what “anomaly” means for your program, define how you’ll evaluate one and let those two decisions drive the detection you build. You can’t meet the intent of INSM with signatures alone, but you don’t necessarily have to reach full process-level depth either. That’s a risk-based call you justify within your own program based on your organization and team.
This post only scratches the surface of what was covered in the webinar. Register for the webinar series and watch the Episode 5 replay for the full discussion, including the complete detection-methods walkthrough and baseline levels discussion. And if you’d like to talk through how any of this applies to your own environment, reach out. We’re here to support you.





.webp)


